Content
Context Engineering: The AI Skill Nobody Teaches
You don’t need a “smarter” AI to get better work out of AI. Most of the time, you need the same model, but with one thing it almost never receives: the right context.
When people tell me “AI didn’t work for me,” what they usually mean is: it worked once, then started guessing. It wrote something that sounded correct, but wasn’t usable. It saved them ten minutes, then cost them an hour of cleanup. That’s not an intelligence problem. That’s a context problem.
Why AI tools feel magical… until they disappoint
The first time you use an AI tool, it feels like cheating. You ask for a summary, you get a clean answer. You ask for a first draft, you get something coherent. Then you try to use it for real work, with real constraints, and it starts slipping.
It forgets the decision you made last week. It doesn’t know your customer’s actual plan tier. It proposes an SOP that ignores your compliance rules. It drafts an email that breaks your brand voice. It “helps” with a meeting recap but misses the one action item that actually matters.
And the worst part is that it often fails confidently. You don’t get an error. You get a plausible output.
This is the trap: we judge AI by how smart it sounds, not by how little we had to fix.
Context engineering vs prompt engineering (the distinction that matters)
Prompt engineering is the craft of writing better instructions. It’s useful, and it’s not going away. But it’s only a slice of the real problem.
Context engineering is everything that determines what the model sees before it answers. Not just the prompt, but the whole input: stable rules, relevant documents, current state, past decisions, tool outputs, and constraints. It’s the difference between giving someone a one-line request and giving them the folder, the policy, the timeline, and the definition of done.
If prompt engineering is how you phrase the ask, context engineering is how you package reality.
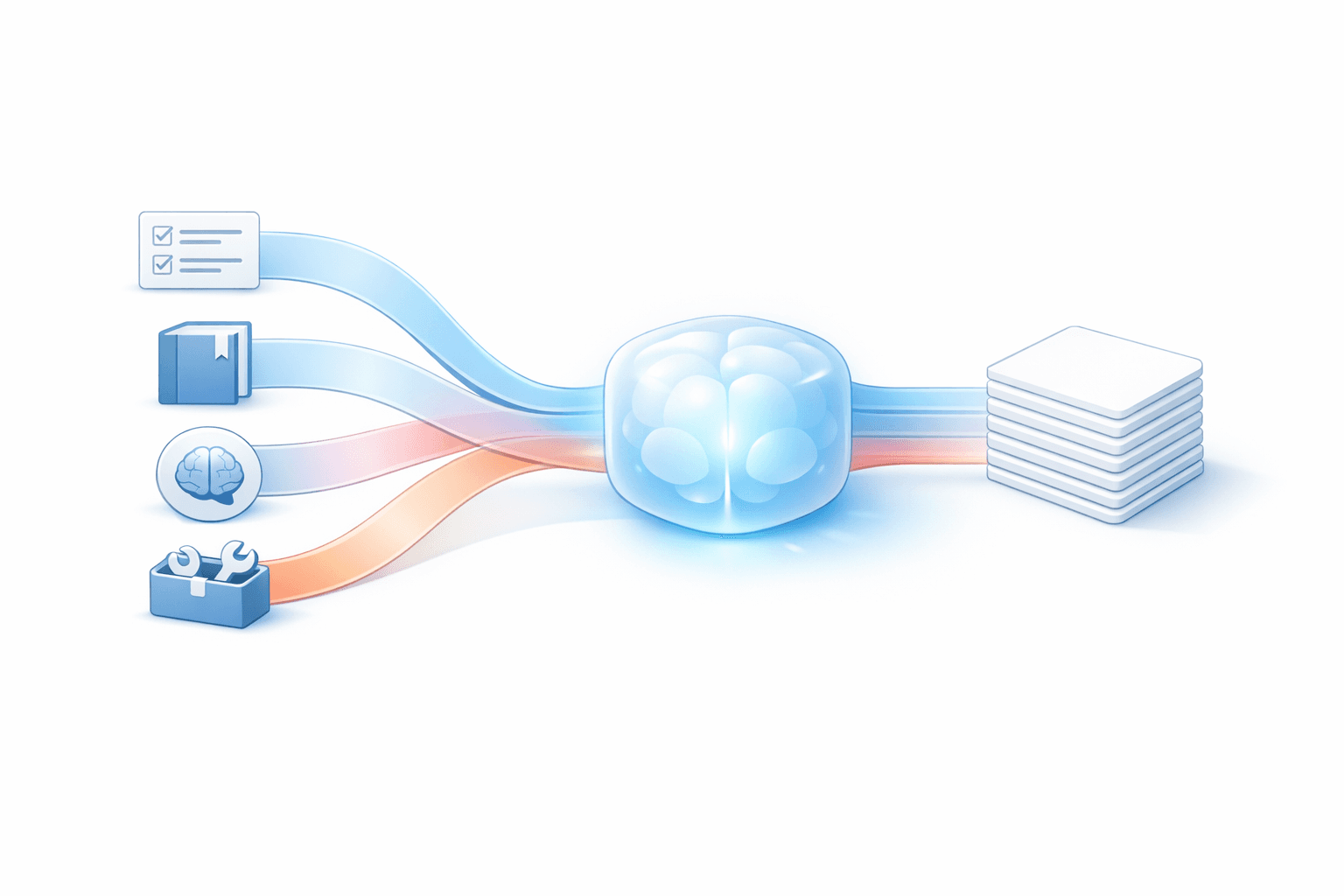
The four building blocks that decide whether AI helps or hurts
Most “AI productivity” failures come down to missing one of four categories of context. You can have a brilliant model and still get garbage if one of these is absent.
Instructions: the rules that stop the model from freelancing
Instructions are the guardrails. They define the role, the tone, the constraints, and what “good” looks like.
If you’ve ever gotten an answer that was technically correct but useless, you probably lacked instructions like: what format you need, what level of detail, what you consider unacceptable, or what sources it must rely on.
In ops terms: this is where you encode your definition of done. If the AI doesn’t know what done means in your company, it will keep shipping “pretty drafts” that create rework.

Knowledge: the facts the AI should not be allowed to guess
Knowledge is the source material: SOPs, internal docs, product specs, pricing pages, strategy memos, meeting notes, customer conversations, past decisions.
Without knowledge, the model has only two options: say “I don’t know” or guess. Most tools let it guess.
This is why generic AI assistants feel great for generic work and fall apart for company-specific work. Your business is mostly edge cases, exceptions, and “we do it this way because of that one incident in March.” That’s not in the model. You have to provide it.
Memory and state: what’s true right now (and what must stay consistent)
There’s a huge difference between “knowledge” and “state.” Knowledge is the reference. State is the current reality: what project you’re on, what you already decided, what’s blocked, what the customer just said, what the priorities are this week.
If you want an AI assistant to behave like an assistant, it needs continuity. Otherwise every request is a cold start and you’ll keep re-explaining yourself.
In practice, state is where most people leak time. They’ll generate a meeting recap, then manually copy action items into their task system, then manually brief the AI again tomorrow because the AI didn’t retain the plan.

Tools: the difference between “sounds right” and “is right”
Tools are how you let the model fetch truth instead of inventing it.
If the AI can look up the latest CRM record, it doesn’t have to hallucinate the account status. If it can read the calendar, it doesn’t have to guess your availability. If it can query your documentation, it doesn’t have to riff on how your onboarding works. If it can inspect a repo or a ticket, it doesn’t have to pretend it understands the codebase.
This is where the assistant stops being a text generator and becomes a worker. Not because it’s more “agentic,” but because it has access to the same systems you use to do the job.
RAG is a context supply chain, not a checkbox feature
Retrieval-augmented generation (RAG) is one of the most important ideas in practical AI: instead of relying on what the model “remembers” from training, you retrieve relevant documents and feed them into the context so the output is grounded.
But here’s the part people miss: RAG is a supply chain. If you feed low-quality inputs, you get low-quality outputs, just faster.
The common failure mode is thinking that more context is always better. It isn’t. Stuffing ten documents into the prompt doesn’t make the model more accurate; it often makes it more confused. You don’t want a context dump. You want a curated, relevant packet.
Quality beats quantity. Clarity beats volume. The goal of retrieval is not to impress the model with how much you know. The goal is to remove ambiguity.

Founder-style examples: where context gaps create hidden rework
Let me make this painfully concrete, because “context” can sound abstract until you watch it burn hours.
SOPs and ops workflows
You ask AI to write an SOP for customer onboarding. It produces a nice document. Then your team has to rewrite it because it ignores the actual steps: the internal approval, the pricing exception flow, the compliance email, the handoff to success.
That rewrite isn’t a writing problem. It’s a missing-knowledge problem. The AI never saw your real onboarding notes, the last three post-mortems, or the current checklist.
Meeting notes that don’t turn into execution
You summarize a meeting and you get a decent recap. But nothing happens after. Tasks aren’t created. Owners aren’t assigned. Deadlines aren’t scheduled. The recap lives in a document and dies there.
This is a state and tools problem. The model needs to know what project this belongs to, what the existing plan is, and it needs the ability to write the tasks back where your team actually works.
CRM and sales follow-ups
You ask AI to draft a follow-up email. It writes something friendly. It also accidentally offers a feature you don’t have, uses the wrong plan name, and references a “trial” the customer never requested.
That’s missing CRM context and missing constraints. You want a system where the AI pulls the account record, last call notes, plan tier, and the exact next step you agreed on. Then it drafts.
Calendar chaos and scheduling
You ask AI to “find time next week.” It proposes times when you’re already booked, forgets your travel day, and schedules across time zones wrong.
That’s a tools problem. Without calendar access, it’s doing fiction writing.
Codebases and product work
People love AI for code snippets. Then they try it inside a real product, and the suggestions ignore the architecture, the conventions, the edge cases, and the constraints that live in the repo and in tickets.
Again: context. A code assistant without repo awareness is a confident autocomplete. Useful sometimes. Dangerous when the system is complex.
The future: better context packaging, not just bigger models
Models will keep improving. Context windows will keep expanding. But the biggest unlock for productivity isn’t waiting for the next model.
It’s packaging your work so an AI can actually operate inside it.
That means your instructions are explicit, your knowledge is accessible, your state is maintained, and your tools are connected. It means you stop treating AI like a magic textbox and start treating it like a system that needs inputs engineered with the same care you’d put into onboarding a new hire.
Once you do that, something shifts. The AI stops guessing. Your edit distance drops. Your team stops “testing prompts” and starts shipping.
That’s context engineering. And it’s the AI skill nobody teaches—because it’s not a trick. It’s infrastructure.

Flo is the founder of Mind the Flo, an Agentic Studio specialized into messaging and voice agents.

